
The "Safe Major" Story Is Breaking
Recently, my dad asked me a question which, in the past, used to have a very simple answer: "What’s the best thing for a student to major in today?"
Five years back, it was an easy answer: computer engineering. However, in 2026, I realized that the answer is no longer the same. The ‘safe bet’ of studying software engineering does not hold as true as it did back then.
The numbers back this up. According to a 2025 report, unemployment among recent computer science grads (ages 22 to 27) hit 6.1%. For context, that’s higher than the average for all recent graduates (5.3%), which is double the unemployment rate of Art History majors.
I don’t think this is just a temporary hiring slowdown. It’s a structural shift in what it means to build software.
From Production to Verification
The reason for this shift is straightforward: headcount is no longer tied to output. The old world (of five years ago) can be defined as a world in which, if a company wanted to build more features, they would need to hire more engineers to write more code. Today we live in a world in which the linkage between lines of code and number of developers is being severed.
According to the 2026 GitLab survey, more than 30% of production code is now AI-generated. The result is a new bottleneck: humans can’t review new code at the same speed to which its being produced.
Historically, the division of labor in software engineering teams was clear: junior engineers wrote the new code, and senior engineers reviewed it. But as AI absorbs the writing part, the economics change. Teams need fewer junior producers and more experienced reviewers who can make judgment calls. In essence, this dwindles the number of opportunities for entry-level junior engineering roles.
The New Control Point: Judgment
Code is now cheap to generate; the expensive resource has shifted to trust. We are moving from a production-led lifecycle to a verification-led one. A recent survey showed that roughly 40% of DevSecOps professionals believe a developer’s primary role in 2026 will be acting as a code reviewer and prompt engineer rather than a traditional coder.
This is why the review layer is becoming the most critical control point. It’s no longer just about catching a syntax error but rather about making human judgment scalable. As code generation continues to accelerate, the rest of the lifecycle compresses toward the review. Merging, testing, security, and deployment are pulled into the human decisions. The “go/no-go” decision becomes the highest-leverage point in the SDLC.
The Battle for the Review Layer
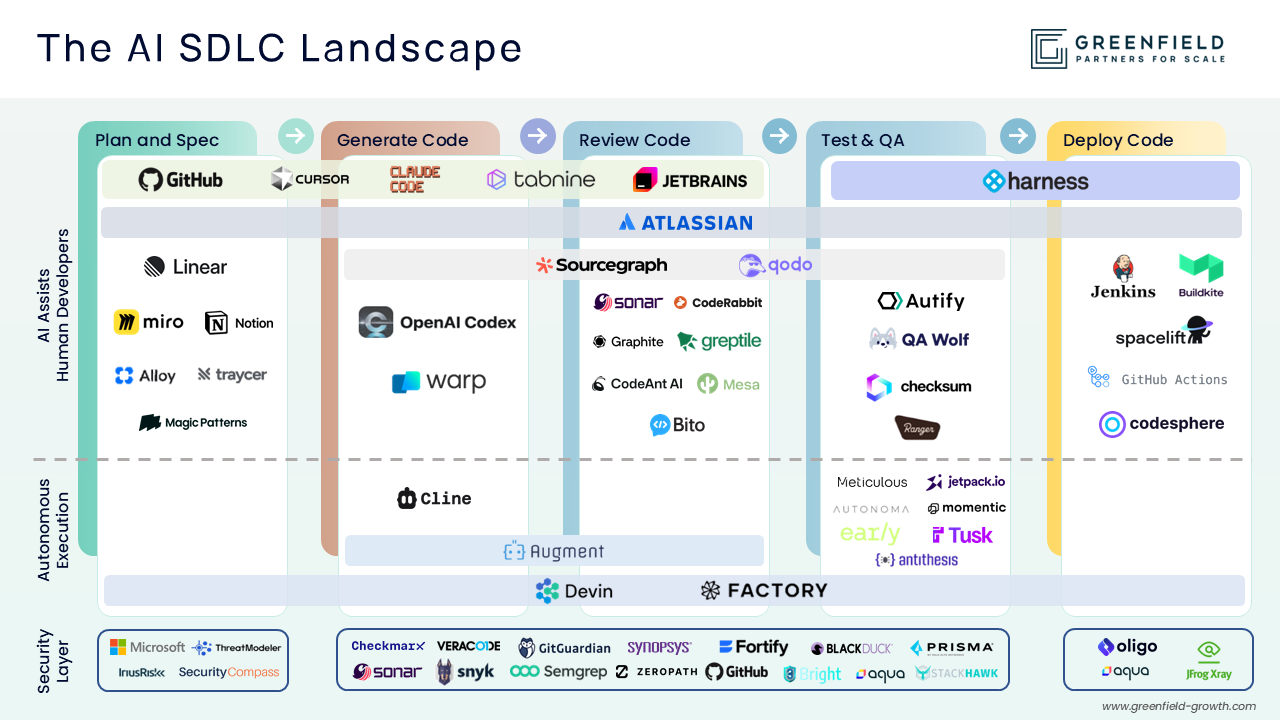
This shift has triggered a new category: integrity platforms. Startups like CodeRabbit, Greptile, and Qodo are betting on the premise that AI should be leveraged to make human judgement scalable.
Automated code review isn’t new. Linters have been enforcing style and syntax for years; static analysis tools like Sonar have flagged known classes of bugs. These tools have played an important role in improving software quality, but they operate on predefined rules and known patterns, which makes them effective at catching obvious issues while leaving them poorly suited for evaluating intent and context.
With recent model advancements, code review tools can now reason across codebases and understand context. They can read an entire pull request, track changes, evaluate how code fits into an existing system, and surface higher level issues (e.g., whether an abstraction makes sense, whether a change introduces risk, whether the implementation actually matches the developer’s intent.)
The belief in these AI-native code review tools hinge on neutrality. If you use a tool like Cursor to write your code, can you trust Cursor to tell you if that code is fundamentally flawed? It’s a conflict of interest. We’ve seen this dynamic play out in observability. Datadog didn’t win by generating infrastructure data but by being the independent source of truth.
Since code review is rooted in judgment, judgment is difficult to trust when a system is validating its own work. In the AI era, we’ve heard from engineers that separation of these tools is important.
The Incumbent Advantage and the Distribution War
Neutrality alone doesn’t win markets. Distribution wins markets. The biggest competitive pressure on the review layer comes from platforms that already sit inside the core developer workflow and can bundle review as a default feature.
GitHub is the clearest example. As Copilot moves beyond generation and into review, the platform can collapse authoring and verification into a one platform where the code, PRs, and teams already live. Atlassian has a similar advantage on the collaboration and workflow side, especially as review becomes tightly coupled with planning and intent tracking rather than just code quality. I believe these companies will start acquisitions soon.
Harness is the other meaningful incumbent vector, but from a different angle. Their positioning is governance: as AI increases the pace of change, testing, security, and deployment become the bottleneck. Harness began with deployment, and their recent Series E announcement signals a deliberate move to shift left to become the governance platform.
Separate from incumbents, adjacent workflow owners such as IDEs and autonomous coding platforms are pulling review into their end-to-end loop. Cursor’s acquisition of Graphite signals a push beyond generation into PR workflow and validation, while Factory and Cognition bundle review directly into autonomous coding so it becomes an embedded capability, not a standalone step.
The "High-Signal" Moat for Startups
The open question is whether standalone startups can survive between these incumbents. I believe there is a path through high-signal data.
GitHub has the repositories, but review-first companies are capturing something more valuable: the corrections. Every time a senior engineer rejects an AI suggestion or leaves a comment, that feedback is extremely high-quality training data.
Raw repositories contain a lot of dead code and legacy decisions. Pull request interactions contain real world expertise and reflect how senior engineers actually evaluate correctness. If review-first startups can use that feedback loop to build an AI reviewer that is meaningfully better than the bundled incumbent product, they can maintain a product edge that offsets the incumbent distribution advantage. That’s the bet for those backing independent review platforms: proprietary judgment data will compound into a defensible reviewer.
The SDLC Bends Toward the Gate
This shift also changes the software development lifecycle itself. Historically, the very core of CI/CD was about speed to shipping new features.
In the era of AI, CI/CD is about confidence. Testing moves earlier and becomes more intensive, driving the emergence of new testing vendors like Early Technologies and Meticulous that are trying to make verification keep pace with AI-era change rates. Models can generate thousands of edge-case tests in a short period of time, but that also raises expectations: passing tests is no longer about basic correctness but about demonstrating robustness across a wide range of failure modes.
Security teams also bear the consequences of AI-generated code, including prompt injection in agentic workflows and accidental secrets exposure. Tools like ZeroPath have been built to make the pre-merge security verification fast enough to match AI-era development speed. The question is not only what can we trust to merge, but what is safe to merge.
The Long-Term Bet
We’re in the early days of this market. Although the trend towards AI-powered code is clearly inevitable, it remains uncertain who will capitalize on the integrity layer.
The long-term winners are not going to be traditional review tools; rather, they are going to be next-gen integrity platforms, whereby code correctness and safety are treated as an infrastructure layer.
There’s also an increasing concern that with more code being AI-generated, the more the next generation of models will end up being trained on this output. Without human oversight, code might look correct but cause significant issues when shipped.
Closing Perspective
AI has clearly made developers more productive, but it has also shifted where risk shows up in the SDLC. For the next generation of students, the safe bet isn’t just about learning how to write code. What matters now more than ever is understanding how these systems behave, how to work with agents, and when something is truly ready to ship.
In practice, that means that there are fewer entry-level engineering roles where the main job is writing code. The ‘safe bet’ of software engineering didn’t disappear; it moved closer to what is senior engineer work. Engineers who can understand systems and make good judgment calls earlier in their careers will have the clearest path forward in this job market.